반응형
1 현행 시스템 분석
1 현행 시스템 파악
1 개념
현행 시스템을 구성하는 하위 시스템, 제공 기능, 연계 정보, 사용하는 기술 요소를 파악
2 절차
- 구성 / 기능 / 인터페이스 파악
- 구성: 기간 업무와 지원 업무로 구분하여 파악
- 기능
- 인터페이스: 데이터의 형식, 통신규약, 연계유형 파악
- 아키텍처 / 소프트웨어 구성 파악
- 아키텍처: 계층별 사용 기술 요소 파악
- 소프트웨어: 제품명, 용도, 라이선스 적용 방식, 라이선스 수 파악
- 하드웨어 / 네트워크 구성 파악
- 파드웨어: 서버 위치, 서버 사양, 수량, 이중화 구현 여부 파악
- 네트워크: 네트워크 장비 파악
3 소프트웨어 아키텍처
1 개념
소프트웨어를 설계하고 전개하기 위한 지침이나 원칙
2 프레임워크
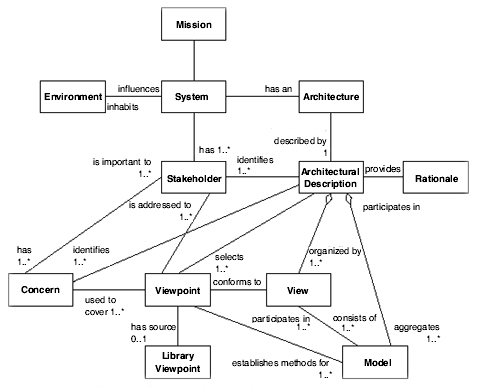
소프트웨어 집약적인 시스템에서 아키텍처가 표현해야 하는 내용 및 이들 간의 관계를 제공하는 아키텍처 기술 표준
- 아키텍처 명세서
- 이해관계자
- 관심사
- 관점
- 뷰
- 근거
3 4+1 뷰
고객의 요구사항을 정리해 놓은 시나리오를 4개의 관저에서 바라보는 소프트웨어적인 접근 방법
- 유스케이스 뷰: 다른 뷰 검증
- 논리 뷰: 설계 모듈의 추상화
- 프로세스 뷰: 런타임 시 테스크, 스레드, 프로세스 간 관계 표현
- 구현 뷰: 개발자 관점
- 배포 뷰: 실행 파일과 런타임 컴포넌트가 해당 플랫폼에 매핑되는 방식
4 현행 시스템 분석서 작성 및 검토
- 자료 수집
- 수집 자료 분석
- 산출물 작성
- 산출물 검토
2 개발 기술 환경 정의
1 시스템 분석
1 운영체제
사용자가 컴퓨터를 좀 더 쉽게 사용하기 위해 지원하는 소프트웨어
- 품질 측면
- 신뢰도
- 성능
- 지원 측면
- 기술 지원
- 주변 기기
- 구축 비용
2 네트워크
데이터 링크를 사용하여 서로에게 데이터를 교환할 수 있도록 하는 기술
OSI 7계층
| 계층 | 설명 | 프로토콜 | 전송단위 |
|---|---|---|---|
| 응용 계층 | 사용자와 네트워크 간 응용서비스 연결, 데이터 생성 | HTTP, FTP | 데이터 |
| 표현 계층 | 데이터 형식 설정과 부호교환, 암/복호화 | JPEG, MPEG | 데이터 |
| 세션 계층 | 연결 접속 및 동기제어 | SSH, TLS | 데이터 |
| 전송 계층 | 신뢰성 있는 통신 보장 | TCP, UDP | 세그먼트 |
| 네트워크 계층 | 데이터 전송을 위한 최적화된 경로 제공 | IP, ICMP | 패킷 |
| 데이터 링크 계층 | 흐름 제어, 동기화, 오류 검출, 재전송 | 이더넷 | 프레임 |
| 물리 계층 | 비트 정보를 전기적 신호 변환 | RS-232C | 비트 |
- 백본망: 다른 LAN이나 부분망 간에 정보를 교환하기 위한 경로 제공
- 라우터: 3계층, 데이터 패킷을 발신지에서 목적지까지 전달하기 위해 최적의 경로를 지정
- 스위치: 2계층, 동일 네트워크 내에서 출발지에 들어온 데이터 프레임을 목적지 MAC 주소 기반으로 빠르게 전달하는 장비
- 게이트웨이: 서로 다른 통신망, 프로토콜을 사용하는 네트워크 간의 통신을 가능하게 하는 장비
- 방화벽: 불법 침입과 불법 정보 유출 방지
3 DBMS
데이터베이스를 만들고, 저장 관리 기능 제공
- 중복 제거
- 접근 통제: 권한에 따른 접근 제어
- 인터페이스 제공
- 관계 표현
- 샤딩/파티셔닝: 구조 최적화를 위해 작은 단위로 나누는 기능 제공
- 무결성 제약조건
- 백업 및 회복
- 성능 측면
- 가용성
- 성능
- 상호 호환성
- 지원 측면
- 기술 지원
- 구축 비용
4 미들웨어
분산 컴퓨팅 환경에서 응용 프로그램과 프로그램이 운영되는 환경 간 통신을 제어해주는 소프트웨어
- 성능 측면
- 가용성
- 성능
- 지원 측면
- 기술 지원
- 구축 비용
2 요구사항 파악
- 자료 수집
- 자료 분석 및 개발 기술 환경 결정
- 요구사항 정의서, 목표 시스템 구성도 반영 및 검토
2 요구사항 확인
1 요구사항
1 개념
고객에 의해 요구되거나, 시스템이 가져야 하는 서비스 또는 제약사항
- 기능적 요구사항: 기능성,완전성, 일관성
- 비기능적 요구사항: 신뢰성, 사용성, 효율성, 유지보수성, 이식성
2 개발 절차
- 도출: 인터뷰, 설문 조사, 브레인스토밍, 워크숍
- 분석: 자료 흐름 지향 분석, 객체지향 분석
- 명세: 자연어에 의한 방법, 정형화 기법 사용 방법
- 확인: 동료 검토, 워크 스루, 인스펙션
3 관리 절차
- 요구사항 협상: 우선순위 설정, 시뮬레이션
- 요구사항 기준선: 공식 회의, 형상 관리
- 요구사항 변경 관리: CCB, 영향도 분석
- 요구사항 확인 및 검증: 확인 및 검증
4 분석 기법
- 요구사항 분류
- 개념 모델링
- 요구사항 할당
- 요구사항 협상
- 정형 분석
5 확인
- 요구사항 검토
- 프로토타이핑: 사용자가 요구한 주요 기능을 프로토 타입으로 구현하여, 피드백을 통해 개선, 보완하여 완성
- 모델 검증
- 인수 테스트
- 요구사항 목록 확인
- 요구사항 정의서 작성 여부 확인
- 비기능적 요구사항 확인
- 타 시스템 연계 및 인터페이스 요구사항 확인
2 시스템화 타당성 분석
검토 항목
- 성능 및 용량 산정의 적정성
- 시스템 간 상호 운용성
- IT 시장 성숙도 및 트렌드 부합성
- 기술적 위험 분석
분석 절차
- 타당성 분석 결과 기록
- 타당성 분석 결과의 이해관계자 검증
- 타당성 분석 결과 확인 및 배포/공유
3 비용산정 모델
1 개념
소프트웨어 규모 파악을 통한 투입 자원, 소요 시간을 파악하여 실행 가능한 계획을 수립하기 위해 비용을 산정하는 기법
2 하향식 비용산정 모델
경험이 많은 전문가에게 비용산정을 의뢰 / 여러 전문가와 조정자를 통해 산정
- 전문가 판단: 경험이 많은 두 명 이상의 전문가에게 비용 산정 의뢰
- 델파이 기법: 전문가의 경험적 지식을 통한 문제해결, 한 명의 조정자와 여러 전문가로 구성
3 상향식 비용산정 모델
세부적인 요구사항과 기능에 따라 필요한 비용 계산
- LoC: 원시 코드 라인 수의 비관치, 낙관치, 기대치를 측정하여 예측치를 구하고, 이를 이용하여 비용 산정
- Man Month: 한 사람이 1개월 동안 할 수 있ㄴㄴ 일의 양을 기준으로 프로젝트 비용 산정
- COCOMO: COnstructive COst MOdel, 개발 노력 승수 결정
- 단순형: 5만 라인 이하의 소프트웨어 개발
- 중간형: 30만 라인 이하의 소프트웨어 개발
- 임베디드형: 30만 라인 이상의 소프트웨어 개발
- Putnam: 소프트웨어 개발 주기의 단계별로 요구할 인력의 분포 가정, 자동화 추정 도구 - SLIM
- FP: 인자별 가중치를 부여하여 기능 점수를 계산
- 정규법: 상세한 기능점수 측정 가능
- 간이법: 프로젝트 초기에 개발 비용 측정 가능
3 분석 모델 확인하기
1 분석 모델 검증
요구사항 도출 기법을 활용하여 업무 분석가가 제시한 분석 모델에 대해 확인
1 방법
- 유스케이스 모델 검증
- 개념 수준의 분석 클래스 검증
- 분석 클래스 검증
3 분석 클래스 스테레오 타입
- 경계: 시스템과 외부 액터와의 상호작용 담당
- 엔티티: 시스템이 유지해야 하는 정보 관리
- 제어: 시스템이 제공하는 기능의 로직 및 제어 다당
3 절차
- 검토 의견 컬럼 추가
- 검토 의견 작성
- 검토 의견 정제
2 분석 모델의 시스템화 타당성 분석
검토 항목
- 성능 및 용량 산정의 적정성
- 시스템 간 상호 운용성
- IT 시장 성숙도 및 트렌드 부합성
- 기술적 위험 분석
절차
- 타당성 검토의견 컬럼 추가
- 타당성 검토의견 작성
- 타당성 분석 결과 검증
- 타당성 분석 결과 확인 및 배포/공유
반응형
'자격증 > 정보처리기사' 카테고리의 다른 글
| 2020 정보처리기사 실기 3. 통합 구현 (0) | 2020.11.13 |
|---|---|
| 2020 정보처리기사 실기 2. 데이터 입출력 구현 (0) | 2020.11.13 |
| 정보처리기사 필기 3. 데이터베이스 구축 - Chapter 5. 데이터 전환 (0) | 2020.08.18 |
| 정보처리기사 필기 3. 데이터베이스 구축 - Chapter 4. 물리 데이터베이스 설계 (0) | 2020.08.18 |
| 정보처리기사 필기 3. 데이터베이스 구축 - Chapter 3. 논리 데이터베이스 설계 (0) | 2020.08.18 |